英偉達近期在數學推理領域邁出了重要一步,推出了兩款專為解決復雜數學問題設計的先進AI模型——OpenMath-Nemotron-32B和OpenMath-Nemotron-14B-Kaggle。
長久以來,數學推理一直是AI技術難以攻克的難題。盡管傳統的語言模型在生成自然語言文本方面表現出色,但在面對需要深入理解抽象概念和進行多步驟邏輯推導的數學問題時,卻常常力不從心。為了解決這一挑戰,英偉達精心打造了這兩款新模型。
OpenMath-Nemotron-32B作為系列中的佼佼者,擁有高達328億的參數,并采用了BF16張量運算來優化硬件效率。這款旗艦模型在多項基準測試中,如AIME 2024、AIME 2025和HMMT 2024-25,均取得了令人矚目的成績。特別是在工具集成推理(TIR)模式下,它在AIME24上的pass@1準確率高達78.4%,通過多數投票機制后,這一準確率更是飆升至93.3%。
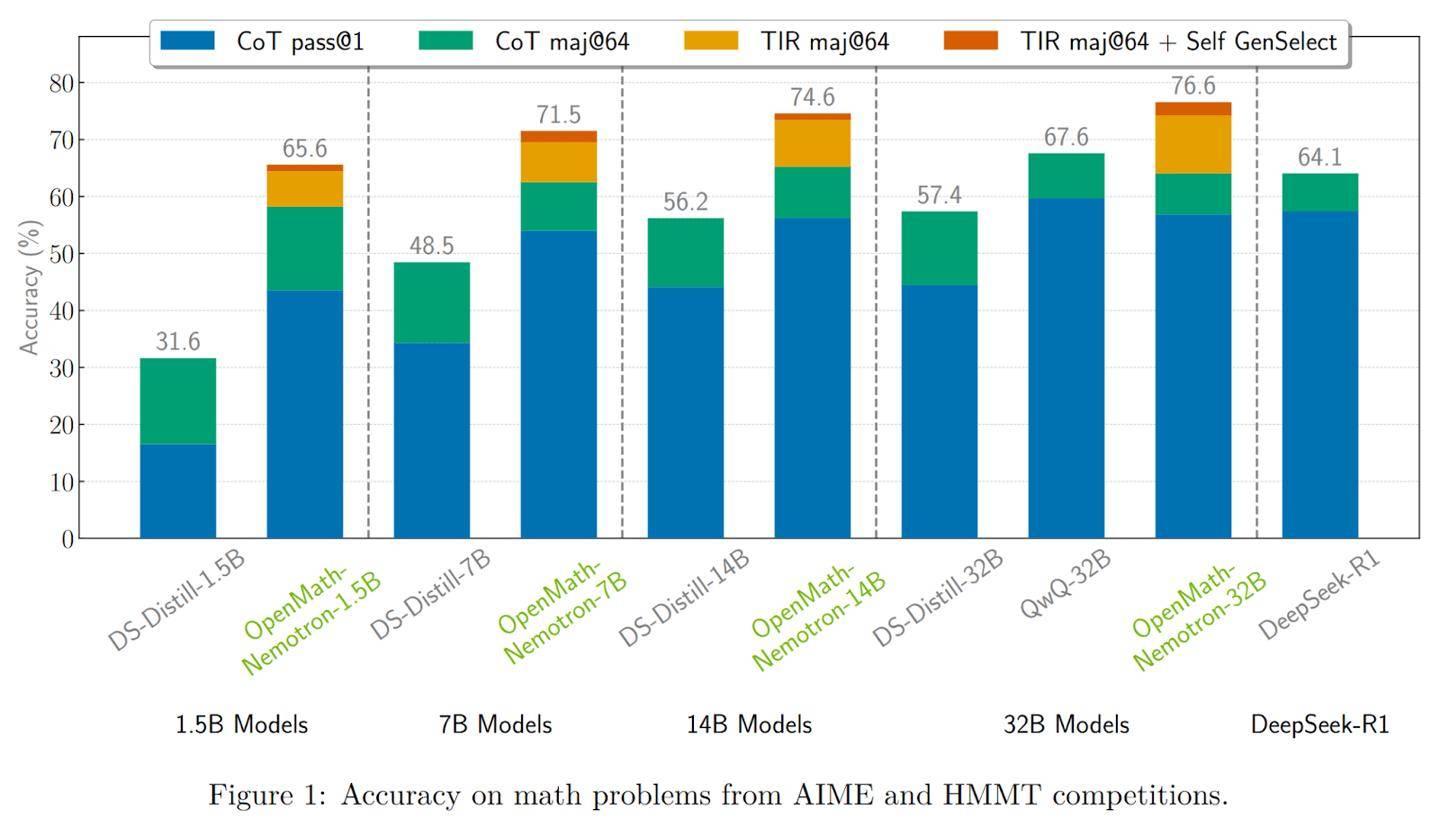
除了強大的性能,OpenMath-Nemotron-32B還提供了多種推理模式以滿足不同需求。用戶可以選擇鏈式思維(CoT)、工具集成推理(TIR)和生成式選擇(GenSelect)三種模式,根據科研或生產環境的具體場景,平衡推理的透明度和答案的精確度。
另一款模型,OpenMath-Nemotron-14B-Kaggle,則是一款更為輕量級的解決方案。它擁有148億參數,專為AIMO-2 Kaggle競賽優化設計。通過精選OpenMathReasoning數據集的子集進行微調,這款模型成功奪得了競賽的桂冠。在AIME24測試中,它在CoT模式下的pass@1準確率為73.7%,而在GenSelect模式下則提升至86.7%。這款模型在保持高質量數學解題能力的同時,更適合資源受限或需要低延遲的場景。
英偉達為這兩款模型提供了完整的開源管道,集成于NeMo-Skills框架中。這意味著開發者可以輕松地通過示例代碼構建應用,獲取逐步解答或簡潔答案。模型還針對NVIDIA的GPU,如Ampere和Hopper架構,進行了深度優化。利用CUDA庫和TensorRT技術,模型能夠高效運行。同時,Triton Inference Server的支持確保了低延遲、高吞吐量的部署,而BF16格式則在內存占用與性能之間取得了完美的平衡。
這兩款新模型的推出,標志著英偉達在數學推理領域取得了重大突破。它們不僅為科研和生產環境提供了強大的工具,也為AI技術的發展開辟了新的道路。