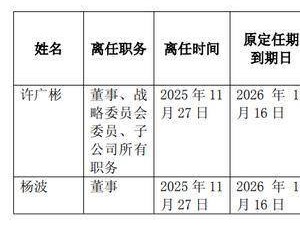
在新加坡南洋理工大學的實驗室里,一只機械臂正反復嘗試抓取桌上的蘋果。這個看似簡單的動作,暴露了當代機器人技術的核心困境——當人工智能在虛擬世界中攻克語言、圖像與代碼時,物理世界的交互仍像一道難以逾越的屏障。就像三歲的孩童能本能地抓取物體,而最先進的機器人系統卻常因蘋果滾落桌面而陷入停滯,這種反差揭示了具身智能領域最根本的挑戰:如何讓機器從“理解世界”跨越到“真正行動”。
王子為的科研軌跡,正是這場跨越“知行鴻溝”探索的縮影。2016年,AlphaGo與李世石的圍棋對決點燃了全球對人工智能的想象,這位清華大學物理系的學生由此轉向AI研究。但真正推動他深入具身智能領域的,是2020年英國利物浦大學開發的“機器人化學家”——這個能在實驗室自主移動、操作儀器的系統,讓他意識到算法與物理世界結合的巨大潛力。同年,他開始探索AI與機器人的融合,首次調試機械臂完成打包任務時,那種“讓機器像人一樣行動”的成就感,成為他科研生涯的重要轉折點。
在卡內基梅隆大學(CMU)的博士后經歷,讓他對機器人研究的節奏有了全新認知。與純AI領域“算法迭代以月為單位”的快速驗證不同,機器人研究的周期被物理世界的復雜性無限拉長。采集數據需要實時操作硬件,訓練模型要應對硬件差異,驗證算法需考慮物理規律——每個環節都充滿不確定性。他參與的樂高積木組裝項目,從2023年啟動到2025年才取得突破,期間團隊花費數年時間優化系統對模糊指令的理解、三維模型生成、動作規劃與執行精度。這種“慢工出細活”的過程,反而讓他沉淀出對關鍵問題的洞察:當機器人遇到訓練數據中未覆蓋的場景時,如何突破模仿學習的局限?
以“抓蘋果”任務為例,當前主流模型能完成標準場景下的抓取,但若蘋果滾落桌面,系統常因缺乏應對“分布外情況”的能力而失效。王子為指出,這暴露了行業面臨的三大挑戰:真實物理環境的數據采集成本高昂,每條數據需數十秒甚至更久;毫米級誤差可能導致任務失敗,精度要求遠超虛擬世界;摩擦、光照等環境變量的微調會徹底改變動作效果,模型需實時建模這些隱性參數。這些難題共同構成了具身智能的“阿喀琉斯之踵”。
針對這些挑戰,他的團隊正探索三條技術路徑。第一條是構建“世界模型”,讓機器人在虛擬環境中預演動作后果,通過“想象”生成訓練數據,降低對真實數據的依賴。第二條是引入推理鏈機制,將長程任務拆解為步驟序列——類似大語言模型的思維鏈,但需同時處理物體間的空間關系與動作間的時間邏輯。第三條則更具顛覆性:用強化學習讓機器人主動探索環境,甚至通過“故意犯錯”積累經驗。例如,機器人可能主動將蘋果推落桌面,在嘗試抓取的過程中學習應對策略,從而擺脫對人類示范數據的依賴。
這種從“被動模仿”到“主動探索”的轉變,標志著機器人向智能體(Agent)的進化。近期研究顯示,通過強化學習訓練的機器人在某些任務中已能達到近100%的成功率,遠超純模仿學習系統。王子為團隊開發的ThinkBot和VLA-Reasoner等模型,正嘗試用蒙特卡洛搜索樹與強化學習優化任務拆解方案,讓機器人自主尋找最優行動路徑。
在南洋理工大學的實驗室里,機械臂的訓練仍在繼續。盡管系統仍會因意外情況失誤,但每次失敗都為模型提供新的學習樣本。王子為認為,在這個充滿不確定性的領域,研究者需要“熱情與快速學習能力”的雙重特質:“頂級研究者必須成為細分領域最了解問題的人,而每前進一步都要面對未知挑戰。只有真正熱愛這個領域、能從突破中獲得成就感的人,才能堅持下去。”
為保持團隊對前沿的敏感度,他推動“論文快講會”制度,要求成員每周快速總結最新研究進展。在應用層面,團隊正與汽車、航空維保、物流等行業合作,通過真實工業場景采集高質量數據,為機器人模型訓練提供基礎。盡管具身智能距離通用機器人系統仍有距離,但這種跨學科合作與持續探索,正在逐步縮小“知道”與“做到”之間的差距。