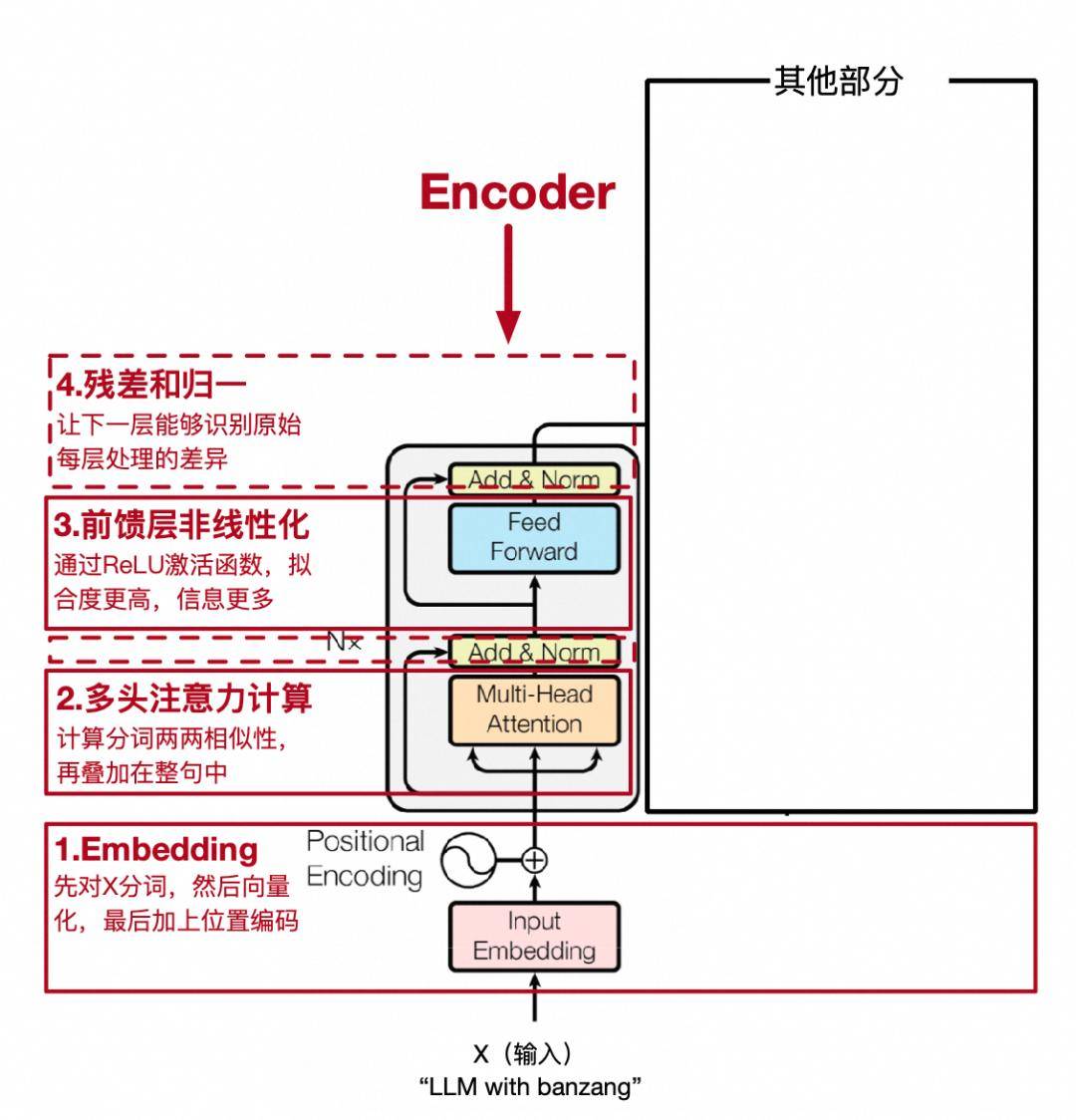
在深度學(xué)習(xí)領(lǐng)域,模型訓(xùn)練過程中的性能優(yōu)化一直是一個(gè)備受關(guān)注的話題。特別是在處理復(fù)雜任務(wù)如自然語言理解時(shí),模型的每一層網(wǎng)絡(luò)都會(huì)增加計(jì)算負(fù)擔(dān),可能導(dǎo)致梯度下降過程中的不穩(wěn)定現(xiàn)象。梯度在下降過程中,有時(shí)會(huì)跳過最優(yōu)解,或在最優(yōu)解附近徘徊,這不僅消耗了大量計(jì)算資源,還可能影響模型的最終性能。
為了解決這一問題,研究者們不斷探索新的網(wǎng)絡(luò)架構(gòu)。2015年,微軟亞洲研究院提出的ResNet架構(gòu),在卷積神經(jīng)網(wǎng)絡(luò)中引入了“跳躍連接”的概念,為Transformer模型提供了靈感。這種連接允許梯度直接反向傳播到更原始的層,從而有效緩解了網(wǎng)絡(luò)深度帶來的“退化”問題。在Transformer中,輸入X不僅被傳遞給每一層進(jìn)行處理,還通過跳躍連接直接與該層的輸出Y相加。這種設(shè)計(jì)使得后續(xù)層能夠?qū)W習(xí)到當(dāng)前層處理與原始輸入之間的差異,而非僅僅依賴于上一層的處理結(jié)果。這種機(jī)制允許網(wǎng)絡(luò)學(xué)習(xí)到恒等映射,即輸出與輸入相同,為模型提供了更簡單的路徑來學(xué)習(xí)正確的映射關(guān)系。

在實(shí)現(xiàn)跳躍連接時(shí),由于X和Y的維度相同,因此可以直接相加。然而,為了確保相加操作的有效性,通常需要對(duì)每一層的輸出進(jìn)行歸一化處理。這一過程包括計(jì)算矩陣每行的均值和方差,然后用每行的元素減去均值并除以標(biāo)準(zhǔn)差(為了避免除以零的情況,通常會(huì)加上一個(gè)小的常數(shù))。最后,通過引入可訓(xùn)練的參數(shù)a和b,來抵消歸一化過程中可能引入的損失。
經(jīng)過跳躍連接和歸一化處理后,Transformer模型的第一階段處理基本完成。為了增加模型的非線性表達(dá)能力,通常會(huì)再添加一個(gè)非線性層,即一個(gè)簡單的全連接神經(jīng)網(wǎng)絡(luò)。這一層通過權(quán)重矩陣和偏置項(xiàng)對(duì)輸入進(jìn)行線性變換,并引入非線性激活函數(shù),從而使模型能夠?qū)W習(xí)到更豐富的特征表示。之后,模型還會(huì)再次進(jìn)行歸一化處理,以確保輸出的穩(wěn)定性。
Transformer模型的這一階段被封裝為一個(gè)獨(dú)立的模塊,稱為編碼器(Encoder)。編碼器能夠捕捉句子中每個(gè)詞與整個(gè)句子的關(guān)聯(lián)性,使得每個(gè)詞向量都包含了句子中所有詞的信息以及它們之間的關(guān)聯(lián)度。這一特性使得Transformer模型在自然語言處理任務(wù)中表現(xiàn)出色,尤其是在機(jī)器翻譯、文本生成等領(lǐng)域。