在2025年高考期間,為確保考試的公平公正,國內多家知名AI大模型,包括騰訊混元、通義千問、Kimi和豆包等,主動暫停了圖片識別問答功能。這一舉措旨在防止高考生利用AI技術作弊。然而,這一做法也引發了一些討論,有人認為這些企業對自家AI大模型的能力或許有些高估,因為之前的相關測試中,AI大模型在解答高考題目上的表現并不盡如人意。
盡管如此,隨著2025年高考全國一卷的部分科目試卷公布,包括語文、英語和數學,媒體和公眾再次將目光投向了AI大模型的能力。特別是對于數學科目,有人提出疑問:這些AI大模型能否像真正的學生一樣,解答出高考的數學題目?
為了驗證這一點,有人選擇了六款AI大模型——DeepSeek、豆包、訊飛星火、文心一言、Kimi和通義千問,進行了一場別開生面的“高考”。測試環境允許AI大模型聯網并使用深度思考功能,所選的數學題目涵蓋了單選、多選、填空和簡答等多種題型。
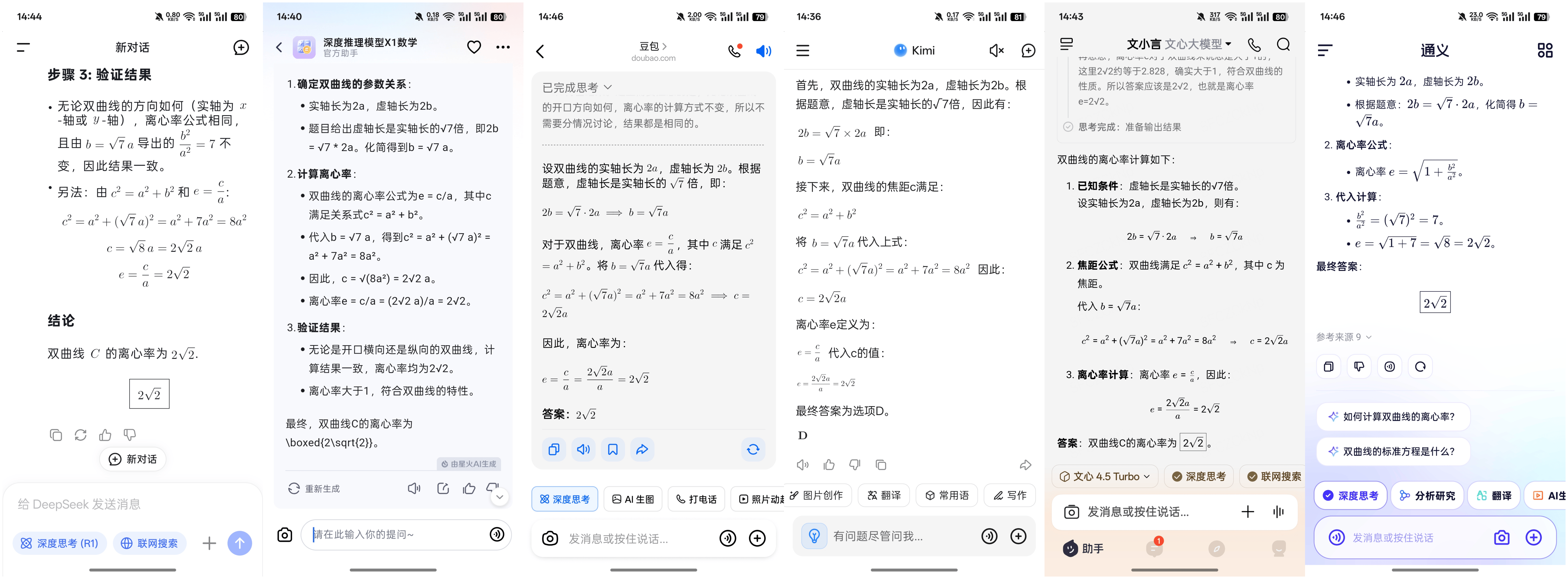
在第一題中,雙曲線的離心率問題對于六款AI大模型來說似乎只是小菜一碟,它們全部得出了正確答案,并且給出了詳細的推理過程。這一輪測試中,所有AI大模型都獲得了滿分。
然而,隨著題目難度的增加,AI大模型之間的表現差異開始顯現。在第二題中,關于三角形和正弦函數的問題讓一些AI大模型陷入了沉思。豆包迅速得出了正確答案,而訊飛星火和通義千問雖然也最終得出了正確答案,但耗時較長。DeepSeek更是耗時接近10分鐘才完成這道題目。
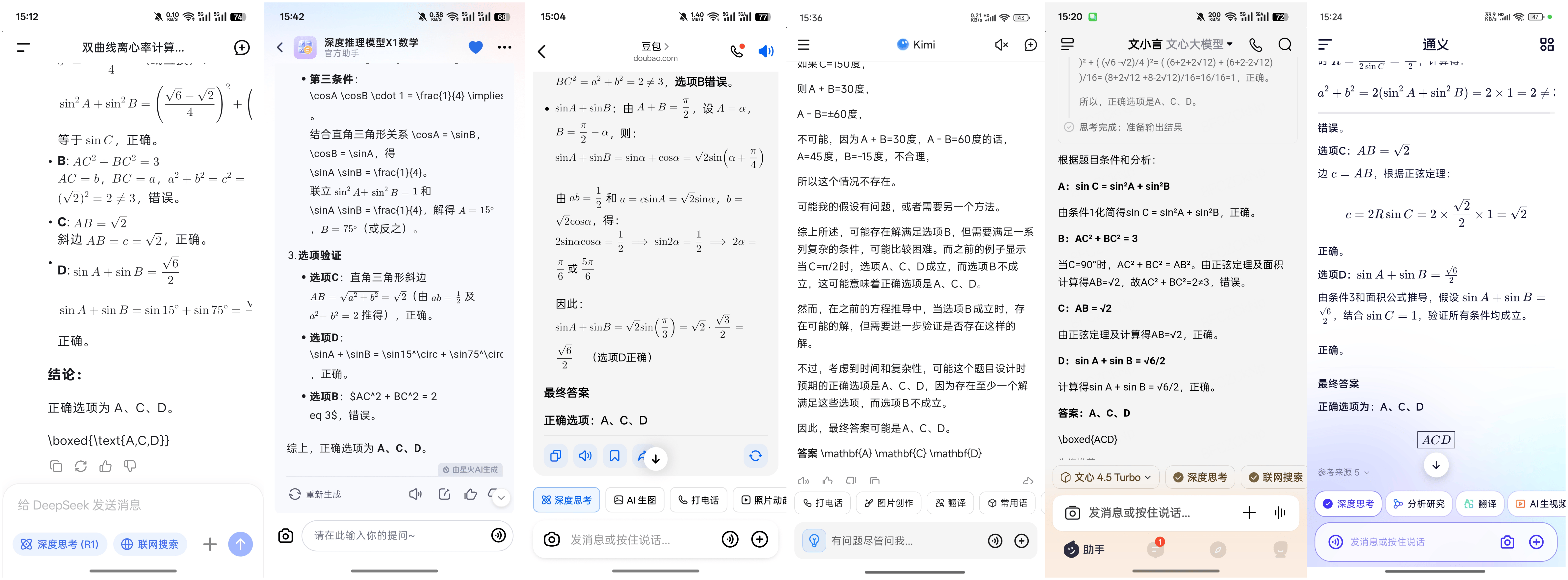
在第三題中,等比數列的問題對于大多數AI大模型來說并不構成太大挑戰,除了豆包在輸出答案時犯了迷糊,排除了一個正確答案外,其他AI大模型都迅速得出了正確答案。然而,在第四題中,一個關于數列和函數的復雜問題再次考驗了AI大模型的實力。豆包、訊飛星火、Kimi、文心一言和DeepSeek依然表現出色,而通義千問則在這一輪測試中敗下陣來。
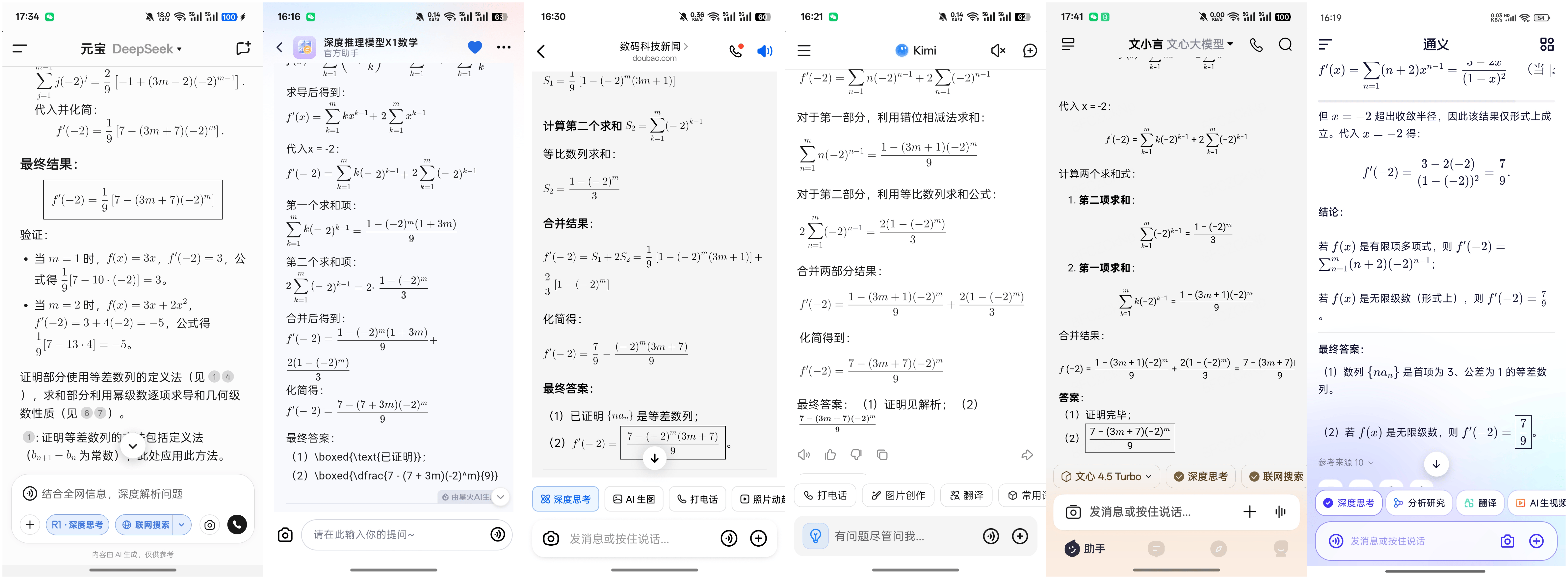

經過四輪激烈的角逐,最終DeepSeek、訊飛星火、Kimi和文心一言以滿分脫穎而出,豆包雖然因一時疏忽丟了三分,但依然展現出了強大的實力。而通義千問雖然在處理簡單問題時表現出色,但在面對復雜問題時則顯得有些力不從心。
這場“高考”不僅檢驗了AI大模型的實力,也讓我們看到了它們在教育和輔導方面的巨大潛力。未來,隨著AI技術的不斷進步,學習機廠商和教育輔導平臺或許可以與這些頭部AI企業合作,共同推動AI教育硬件業務的發展,為學生提供更加高效、智能的學習輔助工具。