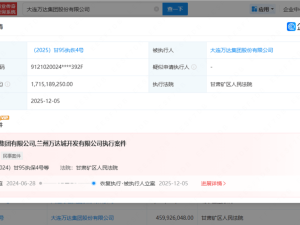
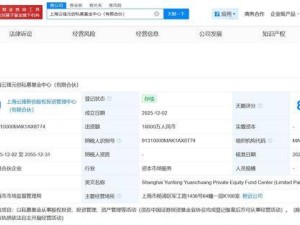
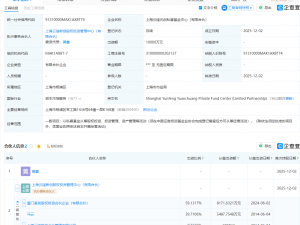
NVIDIA近日宣布推出CUDA 13.1版本,這一更新被官方譽(yù)為自2006年CUDA平臺問世以來最具突破性的升級。其核心亮點(diǎn)在于引入了名為CUDA Tile的全新編程模型,將GPU編程的抽象層級提升至全新高度,為開發(fā)者開辟了更高效的并行計(jì)算路徑。
傳統(tǒng)SIMT(單指令多線程)模型要求開發(fā)者直接管理線程分配、內(nèi)存訪問和同步機(jī)制等底層細(xì)節(jié),而Tile模型通過將數(shù)據(jù)劃分為可獨(dú)立處理的"瓦片"單元,使開發(fā)者只需關(guān)注數(shù)據(jù)塊的計(jì)算邏輯。編譯器和運(yùn)行時(shí)系統(tǒng)會自動完成線程調(diào)度、內(nèi)存優(yōu)化和硬件資源映射等復(fù)雜任務(wù),這種設(shè)計(jì)顯著降低了GPU編程的技術(shù)門檻。
為支撐新模型,CUDA 13.1同步推出了虛擬指令集Tile IR和配套開發(fā)工具cuTile。開發(fā)者現(xiàn)在甚至可以使用Python語言直接編寫GPU內(nèi)核代碼,無需深入掌握CUDA C/C++或底層硬件架構(gòu)。這種變革使得數(shù)據(jù)科學(xué)家和AI研究者能夠更快速地將算法轉(zhuǎn)化為高性能GPU加速應(yīng)用,無需依賴傳統(tǒng)CUDA開發(fā)經(jīng)驗(yàn)。
Tile編程模型并非要取代現(xiàn)有SIMT架構(gòu),而是作為并行選項(xiàng)存在。開發(fā)者可根據(jù)應(yīng)用場景自由選擇編程范式:對于需要精細(xì)控制的計(jì)算任務(wù),仍可使用傳統(tǒng)SIMT模式;而對于數(shù)據(jù)密集型應(yīng)用,Tile模型能提供更簡潔的開發(fā)體驗(yàn)。這種靈活性為構(gòu)建跨架構(gòu)的高層計(jì)算庫奠定了基礎(chǔ)。
技術(shù)層面,Tile IR的引入在硬件與軟件之間構(gòu)建了更厚的抽象層。競爭對手若要支持這種新范式,必須開發(fā)能夠解析Tile IR的智能編譯器,而非簡單進(jìn)行代碼轉(zhuǎn)譯。這種技術(shù)壁壘的提升,客觀上增強(qiáng)了CUDA生態(tài)系統(tǒng)的用戶粘性,進(jìn)一步鞏固了NVIDIA在GPU計(jì)算領(lǐng)域的領(lǐng)先地位。新版本通過降低開發(fā)復(fù)雜度,使得更多非專業(yè)開發(fā)者能夠進(jìn)入GPU加速計(jì)算領(lǐng)域,推動整個(gè)行業(yè)的技術(shù)普及進(jìn)程。