百度今日正式宣布,其備受期待的文心大模型4.5系列已如期向公眾開放源代碼,并同步推出了API服務。此次開源行動,百度慷慨地推出了十款涵蓋不同任務需求的模型,從擁有470億參數的混合專家(MoE)模型到輕量級的30億參數稠密型模型,全面覆蓋文本處理和多模態應用。
百度文心大模型4.5系列的開源不僅包含了完整的權重與代碼,還通過飛槳星河社區、HuggingFace及百度智能云千帆平臺等多個渠道,為開發者提供了便捷的下載和使用途徑。這一系列模型遵循Apache 2.0協議,既支持學術研究,也鼓勵產業應用。
在模型陣容上,百度展示了其在獨立自研模型數量、模型類型多樣性、參數規模、開源的靈活性和可靠性等方面的強大實力。尤為文心大模型4.5系列針對MoE架構提出了一種創新的多模態異構模型結構,這一結構有效促進了從大語言模型向多模態模型的持續預訓練,不僅保持了文本任務的性能,還顯著提升了多模態理解能力。
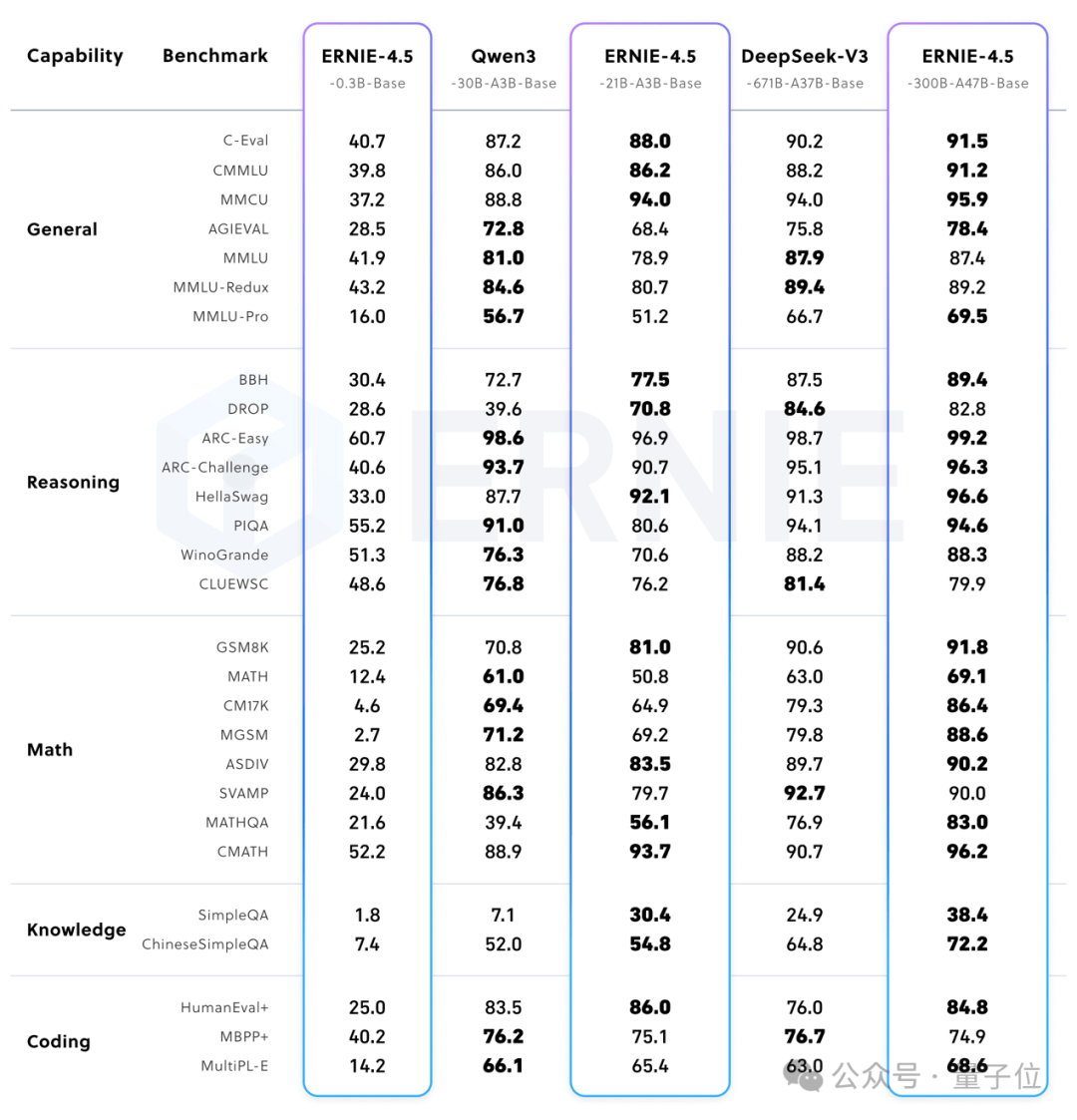
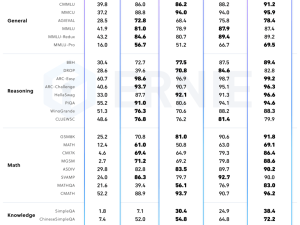
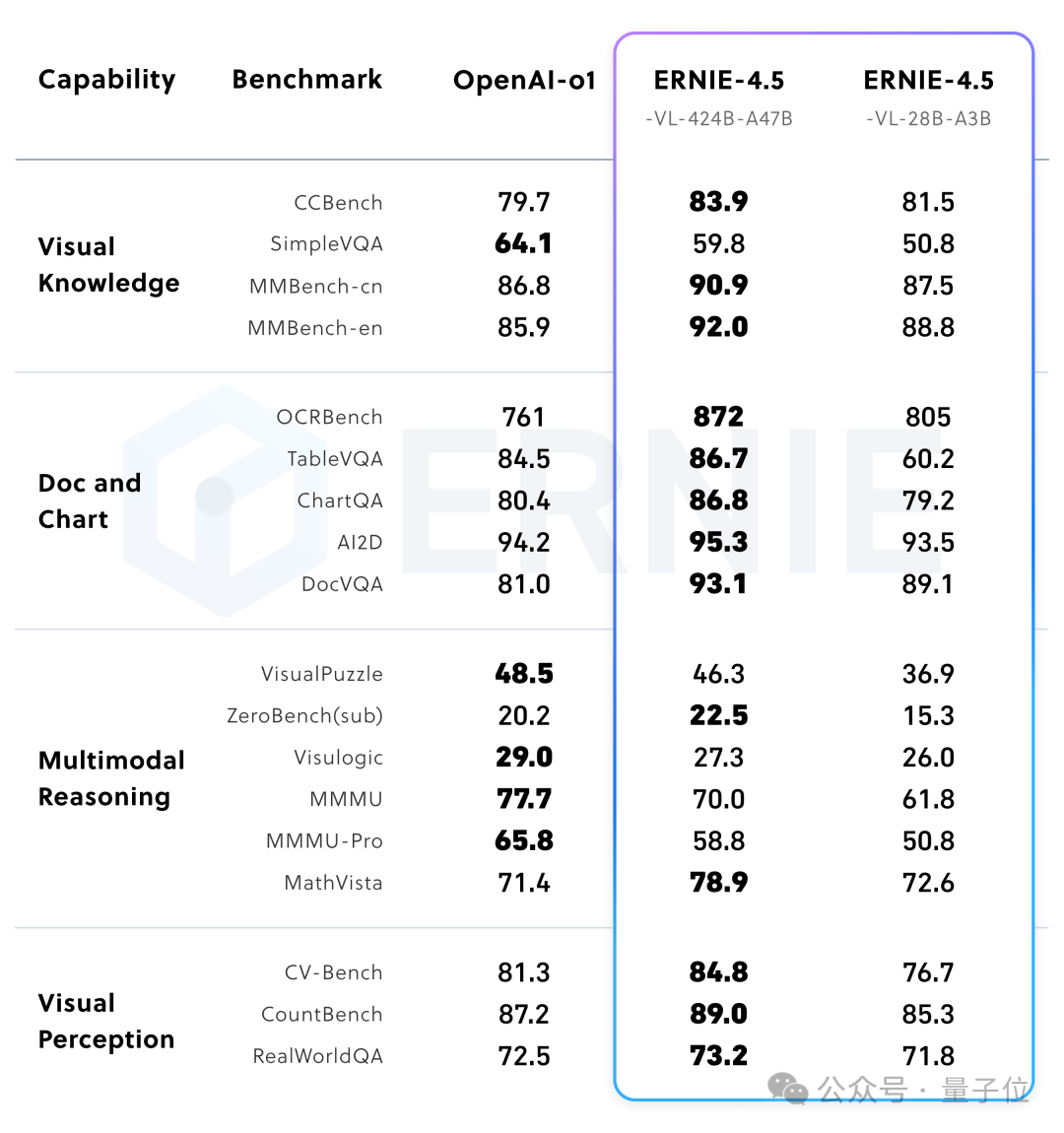
實驗結果顯示,文心大模型4.5系列在多個文本和多模態基準測試中均達到了業界領先水平,特別是在指令遵循、世界知識記憶、視覺理解和多模態推理等任務上表現卓越。在文本模型領域,該系列超越了DeepSeek-V3、Qwen3等模型;而在多模態模型方面,基于強大的視覺感知能力和豐富的視覺常識,文心大模型4.5系列在多項評測中優于閉源的OpenAI模型。
文心大模型4.5系列還注重輕量級模型的開發,其中21億參數的文本模型效果與同級別的Qwen3相當,而28億參數的多模態模型在同級別開源模型中表現最優,甚至能與更大參數的Qwen2.5-VL-32B模型相媲美。這一系列模型均使用飛槳深度學習框架進行高效訓練、推理和部署,預訓練中的模型FLOPs利用率高達47%。
為了進一步提升開發者的體驗,百度還同步發布了文心大模型開發套件ERNIEKit和大模型高效部署套件FastDeploy,為文心大模型4.5系列及廣大開發者提供了開箱即用的工具和全流程支持。這些工具鏈的發布,標志著百度在算力、框架、模型到應用的全棧AI技術優勢上邁出了堅實的一步。作為國內最早投入AI研發的企業之一,百度通過此次“雙層開源”——即框架層與模型層的同步開源,再次展示了其在AI領域的深厚積累和開放共享的決心。