英偉達(dá)公司近日在其官方博客上宣布了一項(xiàng)重大進(jìn)展,推出了一款名為Nemotron-CC的大型英文AI訓(xùn)練數(shù)據(jù)庫。這一數(shù)據(jù)庫規(guī)模龐大,包含了6.3萬億個(gè)Token,其中1.9萬億為精心合成的數(shù)據(jù)。據(jù)英偉達(dá)介紹,這一數(shù)據(jù)庫旨在為學(xué)術(shù)界和企業(yè)界提供更為強(qiáng)大的資源,以推動大語言模型的訓(xùn)練進(jìn)程。
當(dāng)前,AI模型的性能在很大程度上依賴于其訓(xùn)練數(shù)據(jù)的質(zhì)量和數(shù)量。然而,現(xiàn)有的公開數(shù)據(jù)庫在規(guī)模和質(zhì)量上往往存在限制,難以滿足日益增長的訓(xùn)練需求。英偉達(dá)表示,Nemotron-CC正是為了解決這一難題而生。該數(shù)據(jù)庫不僅規(guī)模巨大,而且包含大量經(jīng)過驗(yàn)證的高質(zhì)量數(shù)據(jù),被視為訓(xùn)練大型語言模型的理想選擇。
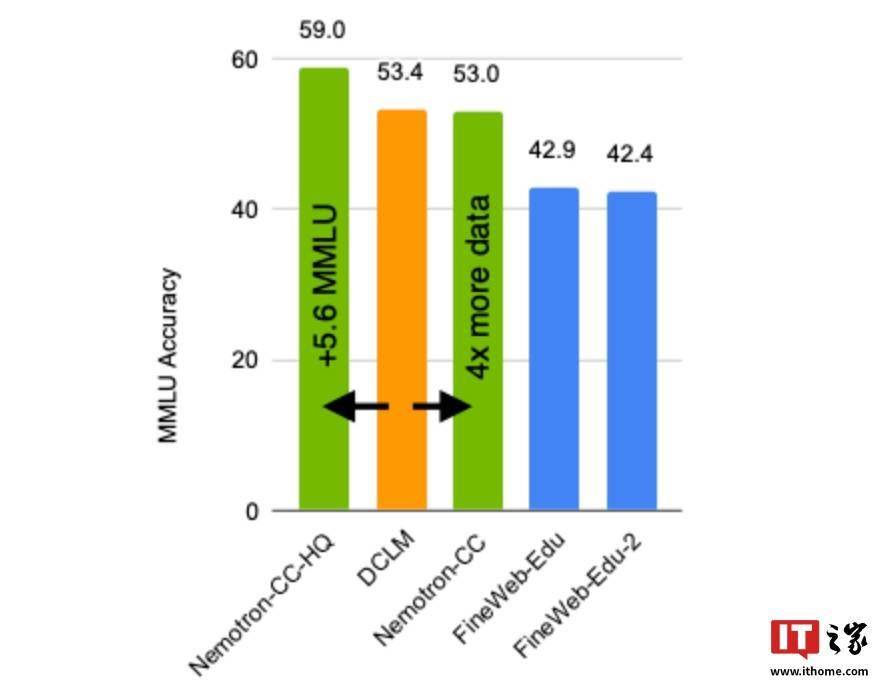
為了驗(yàn)證Nemotron-CC的性能,英偉達(dá)進(jìn)行了多項(xiàng)測試。結(jié)果顯示,與目前業(yè)界領(lǐng)先的公開英文訓(xùn)練數(shù)據(jù)庫DCLM相比,使用Nemotron-CC-HQ訓(xùn)練的模型在MMLU基準(zhǔn)測試中的分?jǐn)?shù)提高了5.6分。使用Nemotron-CC訓(xùn)練的80億參數(shù)模型也在MMLU和ARC-Challenge等多個(gè)基準(zhǔn)測試中取得了顯著的成績提升。
在進(jìn)一步測試中,該80億參數(shù)模型在MMLU基準(zhǔn)測試中分?jǐn)?shù)提升了5分,在ARC-Challenge基準(zhǔn)測試中提升了3.1分,并在10項(xiàng)不同任務(wù)的平均表現(xiàn)中提高了0.5分。這一成績甚至超越了基于Llama 3訓(xùn)練數(shù)據(jù)集開發(fā)的Llama 3.1 8B模型,充分展示了Nemotron-CC在訓(xùn)練大型語言模型方面的優(yōu)勢。
英偉達(dá)在開發(fā)Nemotron-CC的過程中,采用了多種先進(jìn)技術(shù)來確保數(shù)據(jù)的高質(zhì)量和多樣性。例如,他們使用了模型分類器和合成數(shù)據(jù)重述等技術(shù)來優(yōu)化數(shù)據(jù)處理流程。同時(shí),他們還針對特定高質(zhì)量數(shù)據(jù)降低了傳統(tǒng)的啟發(fā)式過濾器處理權(quán)重,從而進(jìn)一步提高了數(shù)據(jù)庫中高質(zhì)量Token的數(shù)量,并避免了對模型精確度造成損害。
英偉達(dá)已經(jīng)將Nemotron-CC訓(xùn)練數(shù)據(jù)庫在Common Crawl網(wǎng)站上公開。用戶可以通過訪問該網(wǎng)站來獲取這一數(shù)據(jù)庫。英偉達(dá)還表示,相關(guān)文檔文件將在稍晚時(shí)候在其GitHub頁面上公布。這將為更多研究人員和開發(fā)者提供便利,推動大語言模型的進(jìn)一步發(fā)展。