在人工智能算力網絡領域,一個新的趨勢正在悄然興起——超節點。這一概念的提出,源于大模型參數的不斷增長和模型架構的持續演變,使得傳統的算力擴容方式已難以滿足需求。Scale-up(縱向擴展)和Scale-out(橫向擴展)作為算力系統擴容的兩個關鍵維度,為我們理解這一趨勢提供了重要視角。
以貨輪運輸為例,當運力需求增加時,Scale-up相當于建造更大的貨輪,而Scale-out則是增加貨輪的數量。在AI領域,Scale-up追求硬件的緊密耦合,以實現高性能計算;而Scale-out則追求彈性擴展,以支撐松散的任務,如數據并行。這兩者在協議棧、硬件和容錯機制上存在顯著差異,導致通信效率各不相同。
以英偉達DGX系列為例,DGX A100通過Infiniband交換網絡實現Scale-out,而DGX H100則通過NVSwitch實現256個H100 GPU的全互聯,形成超節點,從而在通信性能上占據優勢。這種超節點實際上是在單個或多個機柜層面進行的Scale-up,節點內主流通信方案采用銅連接與電氣信號,跨機柜則考慮引入光通信。
英偉達在超節點領域的技術探索尤為引人注目。其推出的DGX GH200系統,將Grace CPU和Hopper GPU封裝在同一塊板卡上,形成“刀片服務器”,并通過內部線纜和光模塊與專門設計的NVLink交換機連接。而隨后的GB200 NVL72超節點產品,則借助第五代NVLink,實現了最大576個GPU的擴容,其中商用方案在機柜層面連接72個GPU,顯著提升了Scale-up的帶寬與尋址性能。
在拓撲結構上,GB200 NVL72中的72個B200 GPU通過單層的NVSwitch實現全互聯,每個B200對超節點內其他71個GPU的通信帶寬均達到1800GB/s,顯著提升了應對通信峰值的能力。與此同時,Scale-out方案則依靠InfiniBand或以太網,通過高帶寬網卡與交換機,帶動光模塊和交換機的放量。
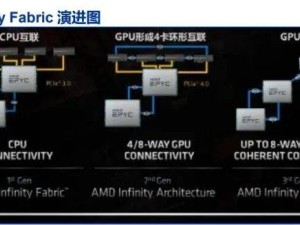
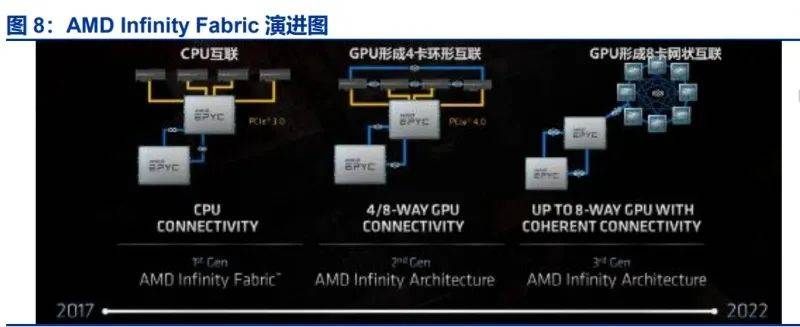
除了英偉達,AMD也在探索超節點的新路徑。其Infinity Fabric互聯總線技術,既用于芯片內部的不同模組,也用于外部互聯。AMD計劃在26H2推出搭載128個MI450X的超節點產品,通過實現以太網Scale-up,打造新的超節點互聯方式。與NVL72不同,MI450X IF128通過IFoE(Infinity Fabric over Ethernet)連接,一定程度上打破了Scale-up和Scale-out的界限。
然而,超節點的發展并非一帆風順。特斯拉的Dojo系統就是一個典型的例子。Dojo是特斯拉專為神經網絡和自動駕駛汽車設計的AI訓練超級計算機,其采用全定制的芯片和軟件棧,與傳統AI架構形成鮮明對比。然而,Dojo的封閉生態和2D Mesh拓撲結構卻成為其發展的重要掣肘。由于硬件設計與傳統GPU架構顯著不同,Dojo在搭建軟件棧時需要自上而下的完全重構,這增加了與主流AI框架對齊的成本。2D Mesh拓撲的彈性較弱,不利于全局通信,不符合主流大模型的趨勢。
面對超節點的挑戰,華為等廠商也在積極探索解決方案。華為認為,超節點的發展需要綜合考慮硬件、軟件和通信協議等多個方面。通過優化硬件設計、提升軟件兼容性和改進通信協議,可以有效解決超節點在擴展性、性能和成本等方面的問題。華為的技術探索為超節點的發展提供了新的思路和方向。