在視頻理解領域,北大與UCSD聯合團隊提出了一項創新框架——VideoOrion,其論文被國際計算機視覺頂會ICCV 2025以高分接收。該研究針對現有Video-LLM模型依賴下采樣或特征聚合導致細節丟失、語義糾纏的問題,提出將視頻中前景物體的時空動態顯式編碼為“對象令牌”(Object Tokens),并與背景上下文令牌(Context Tokens)并行輸入大語言模型(LLM),構建出兼具高效性與可解釋性的視頻理解系統。
傳統方法通常將視頻幀分割為空間網格或聚合特征生成令牌,但這種處理方式容易混淆不同物體的語義信息。VideoOrion的創新之處在于,它將視頻中的對象及其跨幀演化視為獨立語義單元,通過“檢測-分割-跟蹤”三步流水線提取對象動態。具體而言,系統首先利用通用檢測模型GroundingDINO在關鍵幀生成候選框,再通過分割模型SAM細化對象掩碼,最后用跨幀跟蹤器XMem生成隨時間變化的掩碼序列。這些掩碼經過特征池化與投影后,形成語義解耦的Object Tokens,每個令牌對應一個獨立物體的動態信息。
在雙分支編碼架構中,Context Tokens分支采用CLIP或SigLIP模型對采樣幀進行編碼,生成承載背景與場景信息的上下文令牌;Object Tokens分支則通過上述流水線提取對象級動態。兩類令牌被并行輸入LLM進行融合推理,使模型既能捕捉全局場景信息,又能聚焦關鍵對象的細節變化。例如,在描述“紅色三輪滑板車”時,模型不僅能識別其顏色與類型,還能解析“拖地組件”等細節;在分析動作場景時,可精確分解“黑色泳裝跳板后空翻”中的動作要素。
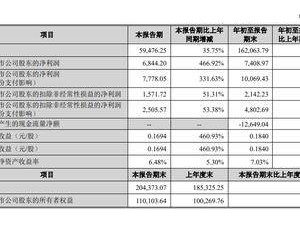
實驗表明,VideoOrion在MVBench、EgoSchema、Perception-Test等五大基準測試中全面超越同規模模型。以7B參數版本為例,其在MVBench上的準確率達63.5%,較VideoLLaMA2提升10.1%;在EgoSchema上得分65.1,漲幅達14.6%。特別在視頻指代任務中,該框架展現出獨特優勢:通過在提示模板中填入目標對象對應的令牌,即可直接回答“這個物體在做什么”等問題。在VideoRef45K數據集上,經少量微調后,其BLEU@4、METEOR等指標均顯著優于Artemis、Merlin等現有方法。
研究團隊通過消融實驗驗證了設計合理性:移除對象分支會導致性能全面下降;預訓練對象分支可提升模型表現,說明對象令牌需先學習基礎語義再與文本對齊;令牌數量控制在64個時模型最穩定,過多會分散注意力。流水線組件替換實驗顯示,RAM++自適應分段策略與XMem跟蹤器的組合效果最佳,較均勻分段或SAM2跟蹤均有明顯優勢。
盡管VideoOrion在性能上取得突破,但研究也指出其局限性:引入專用視覺模型帶來約38.5%的時延開銷,低質量視頻可能導致掩碼不準確;當前仍依賴視頻分支提供上下文,對象-場景融合機制需進一步優化。該框架通過結構化重寫視頻語義,為視頻問答、機器人感知等任務提供了新范式,其雙視角編碼思路或推動多模態領域向更精細化的方向發展。