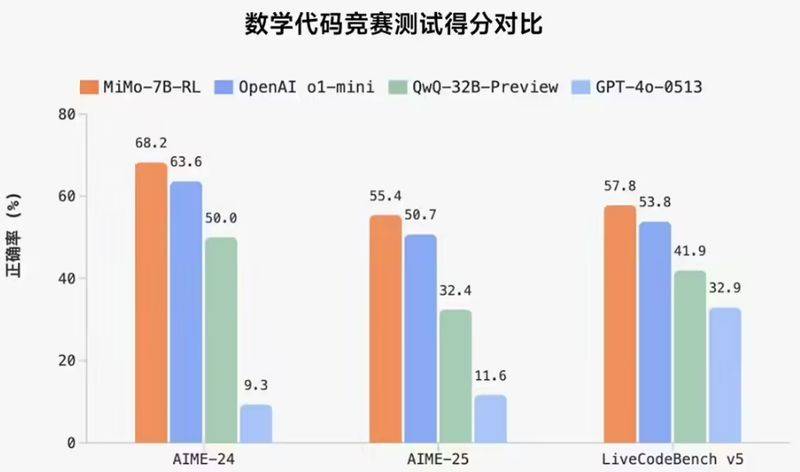
小米大模型團隊近日通過其官方公眾號“Xiaomi MiMo”宣布了一項重要決定:正式開源專為推理任務定制的大模型——Xiaomi MiMo。這款模型在多項公開測評中,如數學推理和代碼競賽,均展現出了卓越的性能,尤其值得注意的是,它僅以7B參數就超越了OpenAI的o1-mini(閉源)以及阿里Qwen的QwQ-32B-Preview(開源),后者規模更為龐大。
MiMo之所以能在推理能力上取得如此顯著的成就,關鍵在于其在預訓練和后訓練階段所采取的創新策略。在預訓練階段,團隊精心挑選并合成了大量富含推理信息的語料,總量達到了約200B tokens。通過分三個階段逐步提升訓練難度,MiMo累計接受了25T tokens的訓練,這一過程極大地豐富了模型對推理模式的認知,為其強大的推理能力奠定了堅實的基礎。
在后訓練階段,MiMo團隊更是引入了高效且穩定的強化學習算法和框架,以進一步提升模型的推理性能。他們創造性地提出了Test Difficulty Driven Reward(測試難度驅動獎勵)機制,這一機制有效地緩解了困難算法問題中獎勵稀疏的難題。同時,他們還引入了Easy Data Re-Sampling(簡單數據重采樣)策略,以確保強化學習(RL)訓練過程的穩定性。
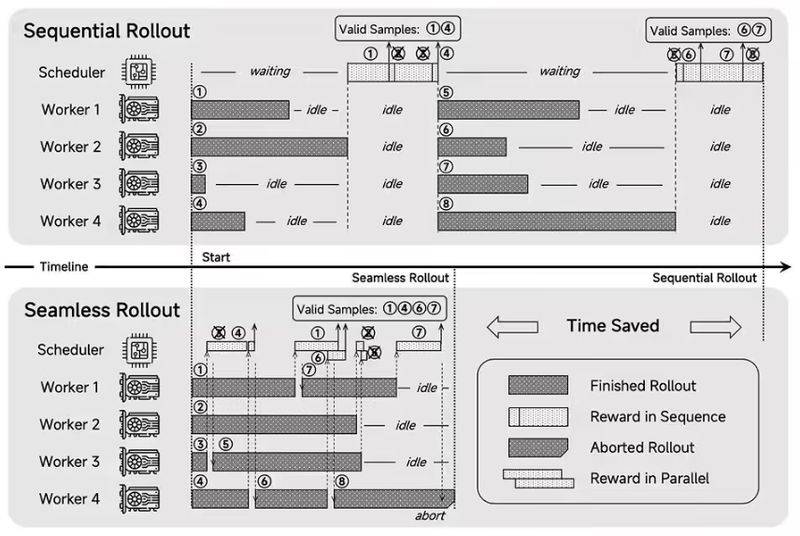
為了進一步提高訓練效率,MiMo團隊還設計并實現了Seamless Rollout(無縫展開)系統。這一系統使得RL訓練的速度提升了2.29倍,驗證速度也提高了1.96倍,從而大大縮短了模型的開發周期。
Xiaomi MiMo的開源,無疑為推理任務的大模型研究注入了新的活力。它以其卓越的性能和創新的技術,為行業樹立了新的標桿,也為廣大開發者提供了寶貴的學習和研究資源。