在人工智能領(lǐng)域,一場關(guān)于大模型的激烈競賽正在悄然上演。近日,阿里巴巴和字節(jié)跳動不約而同地宣布了自家大模型的重大升級,標志著這場競賽進入了新的階段。
3月28日,阿里推出了全新的視覺推理模型QVQ-Max,該模型不僅具備看圖、讀視頻的能力,還能解決復(fù)雜的數(shù)學(xué)問題。而字節(jié)方面,其豆包模型也迎來了新版“深度思考”功能的測試,該功能允許模型在推理過程中動態(tài)發(fā)起搜索,實現(xiàn)“邊想邊搜”的智能化體驗。
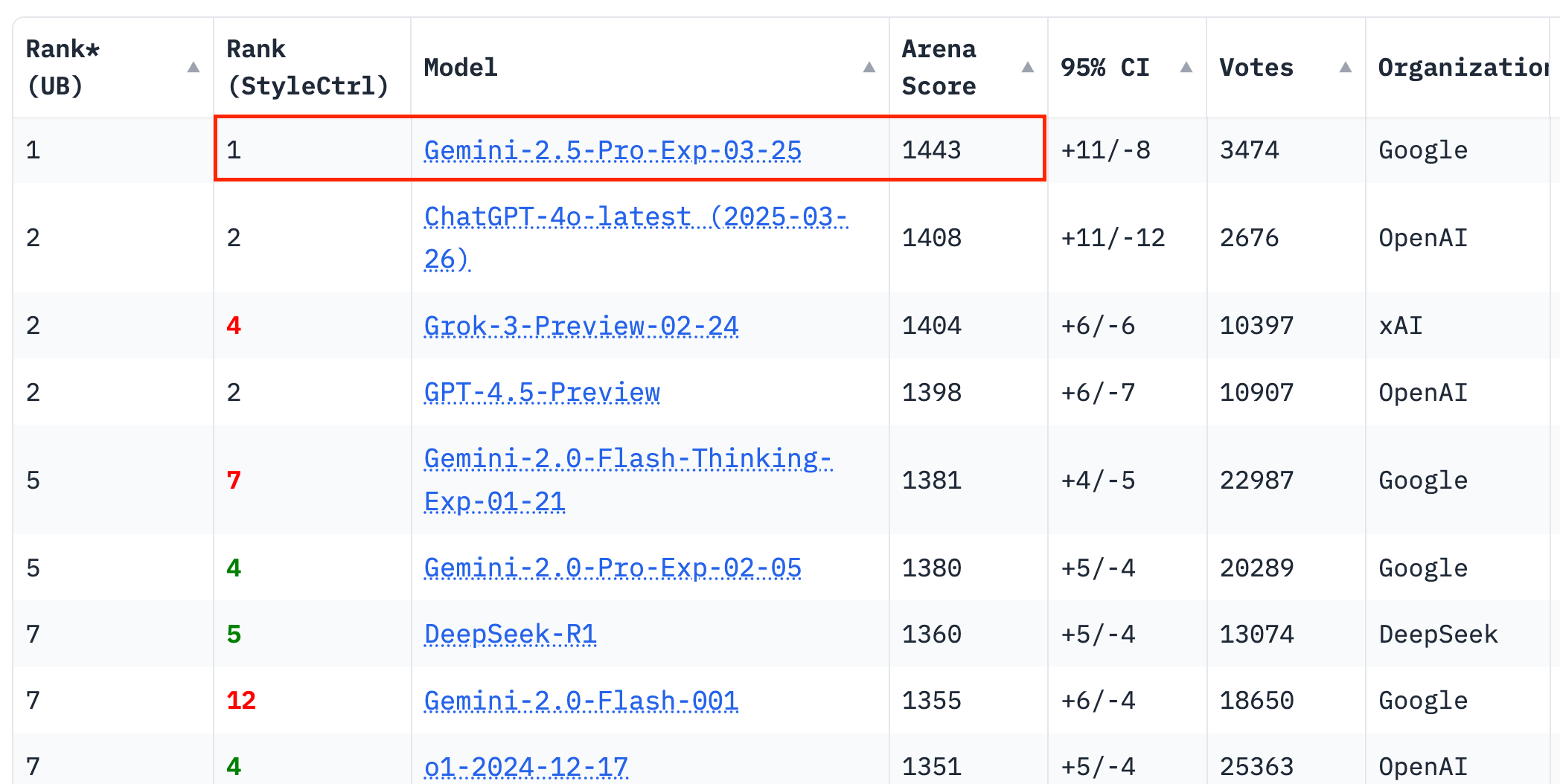
事實上,這兩家公司的升級并非孤立事件。近期,多家主流大模型都發(fā)布了新版本。DeepSeek推出了V3-0324版本,在推理、寫作、編碼能力上均有提升;Google則推出了Gemini-2.5-Pro,該模型在LMArena榜單上取得了40分的優(yōu)異成績,領(lǐng)先其他模型;OpenAI也不甘落后,其GPT-4o的圖像生成功能得到了顯著增強。
這一系列更新,無疑讓大模型領(lǐng)域的競爭變得更加激烈。從圖像生成到視覺推理,從多模態(tài)到超長上下文,各大模型都在全方位提升自己的能力。這場競賽,已經(jīng)不僅僅局限于功能的比拼,更是質(zhì)量、智能體時代基礎(chǔ)模型提供能力的全方位較量。
阿里的QVQ-Max,以其強大的視覺推理能力脫穎而出。該模型能夠“看懂”圖表、照片,甚至對視頻內(nèi)容進行理解,結(jié)合這些信息進行分析、推理,給出解決方案。無論是復(fù)雜的幾何圖形還是日常生活中的照片,QVQ-Max都能快速識別出關(guān)鍵元素,并進一步分析這些信息,結(jié)合背景知識得出結(jié)論。

而字節(jié)的豆包新版“深度思考”功能,則主打推理進階。該功能支持模型在思維鏈條展開的同時動態(tài)發(fā)起搜索,實現(xiàn)“邊想邊搜”。在實際應(yīng)用中,豆包會在思考過程中搜索資料,不斷通過搜索補充信息再思考,從而更準確地回答用戶的問題。

DeepSeek的V3-0324版本,雖然只是小版本升級,但每一點都變得更加強大。該版本借鑒了DeepSeek-R1在模型訓(xùn)練中使用的強化學(xué)習(xí)技術(shù),針對推理、寫作、編程能力做了進一步優(yōu)化。新版模型在前端開發(fā)能力上更為出色,能生成更具現(xiàn)代設(shè)計感的網(wǎng)頁結(jié)構(gòu);寫作方面則明顯提升了中文中長篇文本的邏輯性和通順度。
Google的Gemini 2.5 Pro,則是此次升級中的一大亮點。作為Google首個“全能型智能體底座”模型,Gemini 2.5 Pro在對話能力上技壓群雄,同時在編碼、數(shù)學(xué)、視覺推理、搜索調(diào)度等能力上都得到了全面增強。該模型正在將“大語言模型”推向“高可信度、多輪決策型智能體”的方向演進。
最后,不得不提的是OpenAI的GPT-4o。此次升級中,GPT-4o的原生圖像生成功能無疑是最吸引眼球的。無數(shù)網(wǎng)友在嘗試新版本的圖像生成功能后,紛紛表示效果震撼。GPT-4o不僅提高了對復(fù)雜指令的理解能力,還顯著提升了圖文混排渲染的可控性。尤其是在生成圖像中的文字內(nèi)容上,準確率大幅提升。新版GPT-4o還支持多輪對話過程中連續(xù)地修改圖像風(fēng)格與構(gòu)圖元素,逐步調(diào)優(yōu),視覺一致性更強。

隨著各大模型的不斷升級,智能體時代已經(jīng)逼近。大模型們正在全方位補齊能力,為智能體的爆發(fā)做準備。推理能力、內(nèi)容生成質(zhì)量、系統(tǒng)調(diào)度能力……這些基礎(chǔ)能力的全方位提升,正在讓這場競賽變得越來越激烈。而在這場競賽中,誰能夠脫穎而出,成為智能體時代的領(lǐng)航者,讓我們拭目以待。