隨著人工智能大模型參數規模從千億邁向萬億級,智算集群對存儲系統的需求正經歷顛覆性變革。以GPT-4為例,其1.8萬億參數的模型訓練需在2萬張A100 GPU上持續運行90天,期間產生的數據吞吐量高達PB級,僅單個checkpoint文件就達4TB。這種超大規模計算場景下,傳統存儲方案在協議兼容性、吞吐性能、數據管理效率等維度暴露出嚴重短板,成為制約AI訓練效率的關鍵瓶頸。
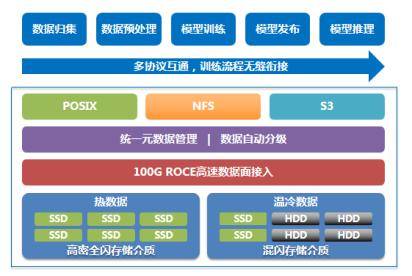
在數據全生命周期管理中,不同訓練階段對存儲協議的需求呈現顯著差異。數據歸集階段需處理跨地域、跨網絡的PB級非結構化數據,涵蓋文本、圖像、視頻等多元格式,對象存儲因其跨域傳輸優勢成為首選;預處理階段則要求對數據進行清洗、脫敏和格式轉換,S3協議與NFS協議需并行工作;模型訓練階段對存儲系統提出更高要求,既要支持訓練數據的高速讀寫,又要實現checkpoint的秒級保存與恢復,文件存儲成為核心載體;模型發布階段則需通過對象存儲實現廣域網部署。傳統方案采用對象、文件、塊存儲獨立集群的模式,導致數據在不同系統間反復遷移,PB級數據拷貝耗時長達數天,GPU因等待數據傳輸產生的空閑時間超過15%,直接拉低整體訓練效率。
存儲系統面臨的性能挑戰呈現指數級增長。當1750億參數的GPT-3模型進行checkpoint保存時,數萬張GPU會同時發起4TB級數據寫入,引發"寫風暴"。這種突發性I/O洪峰對存儲集群的聚合帶寬提出嚴苛要求,而傳統方案受限于故障域約束,集群節點數難以突破,導致存儲穩定性與性能需求形成尖銳矛盾。更嚴峻的是,數據冷熱狀態隨訓練進程動態變化,熱數據需駐留在高成本SSD介質,冷數據則應遷移至HDD存儲。但傳統方案缺乏自動分級能力,導致高性能存儲長期被低頻數據占用,資源利用率不足40%,同時需額外投入算力進行人工數據搬遷。
針對上述痛點,中國移動創新提出多協議融合存儲架構,通過四大核心技術實現存儲系統質變。在介質層構建雙池架構:熱數據池采用全閃介質,溫冷數據池采用混閃配置,緩存層部署SSD+HDD混合存儲;網絡層部署雙100Gb RoCE高速互聯,構建AI集群與存儲集群間的低時延數據通道;協議層基于統一元數據管理,實現POSIX、NFS、S3協議的無縫互通,訓練數據無需跨池拷貝;管理層開發智能分級引擎,根據數據訪問頻次自動在全閃池與混閃池間遷移數據。該架構在哈爾濱1.8萬卡智算中心的實踐表明,48PB集群可提供6.4TB/s讀帶寬和3.5TB/s寫帶寬,單個checkpoint保存時間壓縮至秒級,較傳統方案提升3倍性能。
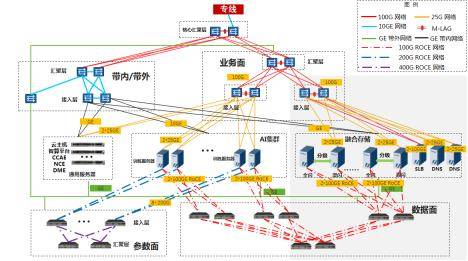
商業化部署成效顯著,哈爾濱節點建設的150PB融合存儲系統包含60PB全閃存儲和90PB混閃存儲,支撐九天千億參數大模型訓練效率提升20%。多協議融合技術消除數據冗余存儲,使混閃存儲容量需求降低40%;高聚合帶寬設計避免GPU等待數據傳輸,算力利用率提高5%;智能分級機制實現數據自動流動,減少20%的全閃空間占用。該創新方案榮獲2024年"華彩杯"算力大賽全國總決賽一等獎,相關技術標準已在中國通信標準化協會立項,推動行業存儲架構向統一元數據、多協議互通、智能管理方向演進。
中國工程院院士指出,存力、算力、運力的均衡發展是發揮計算效能的關鍵。在智算集群規模突破萬卡級的新階段,存儲系統正從被動支撐轉向主動賦能,通過架構創新實現數據流動效率與計算資源利用率的雙重提升。這種變革不僅優化了AI訓練的經濟性,更為超大規模模型研發提供了可靠的存儲基礎設施保障。