AMD近期揭曉了其銳龍AI MAX+ 395 “Strix Halo” APU在DeepSeek R1 AI基準測試中的卓越表現,這一成績遠超NVIDIA RTX 5080桌面版顯卡,性能提升幅度超過3倍。
這款APU集成了強大的硬件配置,包括基于Zen 5架構的16核、32線程處理器,以及擁有50 TOPS算力的XDNA 2神經處理單元(NPU)。它還配備了集成顯卡,為用戶提供全面的計算體驗。
值得注意的是,RTX 5080顯卡僅配備16GB的VRAM,這在處理大型語言模型時顯得力不從心。相比之下,Strix Halo APU提供了高達128GB的統一內存,并可根據需求靈活分配,最多可將96GB內存用作顯存,從而在處理大型AI模型時展現出顯著優勢。
AMD在基準測試中采用了多種消費者AI工作負載,其中包括由llama.cpp驅動的應用程序LM Studio。測試結果顯示,當LLM模型大小超過RTX 5080的16GB VRAM限制時,Ryzen AI MAX+ 395的性能優勢尤為突出,其性能相比RTX 5080提升了3.05倍。

不僅如此,與更高端的RTX 5090(配備32GB顯存)相比,Strix Halo APU在處理大型模型時依然占據絕對優勢。這得益于其龐大的128GB統一內存,為用戶提供了更多的靈活性和處理能力。
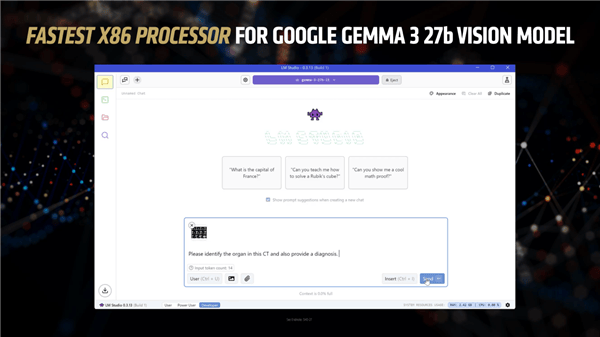
AMD還強調了銳龍AI MAX+ 395相對于其他競品,如Copilot+和英特爾產品的顯著優勢。在性能方面,與英特爾Arc 140V相比,Ryzen AI MAX+ 395在token吞吐量上實現了最高2.2倍的提升。對于小型模型如Llama 3.2 3b Instruct,其首個token生成時間最快可達4倍。在處理7-8B參數模型時,速度提升最高可達9.1倍。在處理14B參數模型時,Ryzen AI MAX+ 395的性能比英特爾酷睿Ultra 258V快12.2倍。
在內存方面,銳龍AI MAX+ 395提供了高達128GB的統一內存,而競爭對手的最大內存僅為32GB。這一優勢使得Strix Halo APU能夠運行其他APU無法處理的大型模型,如谷歌Gemma 3 27B Vision。