近日,一款源自中國的AI大模型DeepSeek,在全球范圍內(nèi)引發(fā)了廣泛關(guān)注與討論。這款模型的出現(xiàn),不僅令全球科技界為之震動,更在金融市場掀起了軒然大波。
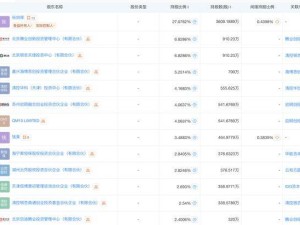
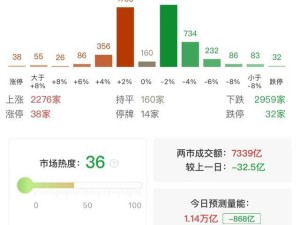
據(jù)悉,上周五,全球股市中的科技巨頭英偉達(dá)遭遇了巨額拋售,市值瞬間蒸發(fā)千億美金。而今日,美股算力概念股亦全線暴跌,其中英偉達(dá)、博通等公司的盤前跌幅均超過10%,直接導(dǎo)致納斯達(dá)克100指數(shù)盤前下跌3%。與此同時,A股市場中的算力硬件股亦未能幸免,銅高速連接、CPO等板塊領(lǐng)跌,股王寒武紀(jì)盤中跌幅一度達(dá)到10%,港股中芯國際同樣大幅下跌逾10%。

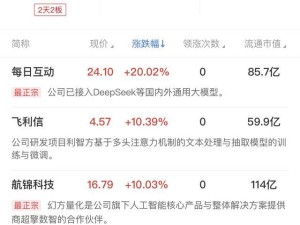
DeepSeek,這款半路殺出的黑馬,究竟是何方神圣?據(jù)了解,DeepSeek由幻方公司在2024年底推出,其最新版本DeepSeek-v3僅使用了550萬元和2000張顯卡進行訓(xùn)練,卻達(dá)到了與OpenAI耗資數(shù)億打造的模型相當(dāng)?shù)男Ч_@一成就,不僅震驚了全球,更被硅谷譽為“神秘的東方力量”。而隨后發(fā)布的推理大模型DeepSeek-R1,同樣以極低的成本(600萬美元),實現(xiàn)了與OpenAI等巨頭相媲美的性能。
DeepSeek的火爆出圈,不僅創(chuàng)下了下載率神話,更在IOS美國區(qū)和中國區(qū)免費榜上雙雙登頂。這一成就,無疑進一步加劇了其在全球范圍內(nèi)的影響力。

DeepSeek的出現(xiàn),對全球科技產(chǎn)業(yè)產(chǎn)生了深遠(yuǎn)的影響。在高端芯片受限的背景下,中國企業(yè)如何能夠以極低的成本訓(xùn)練出與科技巨頭相媲美的大模型,成為了全球關(guān)注的焦點。而當(dāng)用相對較少的算力就能獲得強大的AI模型時,是否意味著動輒千萬億美元的算力戰(zhàn)將走向泡沫?這一問題,同樣引發(fā)了業(yè)界的廣泛討論。
meta等科技巨頭已經(jīng)陷入了恐慌,緊急組建多個小組來研究DeepSeek如何降低訓(xùn)練和運行大模型的成本。業(yè)內(nèi)認(rèn)為,DeepSeek通過強化學(xué)習(xí)的方式,讓模型具備了“自我進化”的特性,這一發(fā)現(xiàn)僅次于GPT的智力涌現(xiàn)。而這種讓模型在RL環(huán)境中自我探索的創(chuàng)新方式,本身可能同樣讓AI競賽來到了一個新的頓悟時刻,超強性能的模型將不再獨屬于算力巨頭,而是屬于每一個人。

與此同時,ETF市場的兩級分化同樣令人矚目。一邊是“迷你”貨幣ETF早盤繼續(xù)高溢價上漲,而另一邊,前期瘋狂炒作的跨境ETF則集體跌停。由于AI硬件股的大跌,導(dǎo)致算力含量更高的相關(guān)ETF也遭遇重挫。


盡管A股市場在春節(jié)前最后一個交易日表現(xiàn)不佳,但周末卻迎來了兩大重磅利好消息。一是第二批長期股票投資試點正式批復(fù),將為A股帶來520億的中長期資金。二是證監(jiān)會發(fā)布了《指數(shù)化投資高質(zhì)量發(fā)展行動方案》,旨在積極推動股票ETF、債券ETF等指數(shù)化投資產(chǎn)品的發(fā)展,并降低指數(shù)基金的投資成本。