蘋果公司近日在其官方博客上深入分享了其在人工智能領域的隱私保護技術細節,重點聚焦于差分隱私與合成數據在Apple Intelligence服務中的應用。
差分隱私技術的運用,為AI的進化筑起了一道堅實的隱私防線。以Genmoji表情生成為例,當用戶選擇分享設備分析數據時,系統并非簡單收集所有指令,而是通過一種隨機噪聲算法,僅捕獲那些高頻出現的指令,如“戴著牛仔帽的恐龍”。個性化且低頻的指令則被排除在外,且所有收集的數據均與設備ID完全分離。這一機制確保了用戶隱私的同時,也優化了多實體組合表情的生成準確性。設備端在提交數據時,會隨機返回真實指令或干擾信號,只有當某條指令被大量設備同時提交時,系統才會對其進行識別,這一過程不涉及任何敏感信息的泄露。
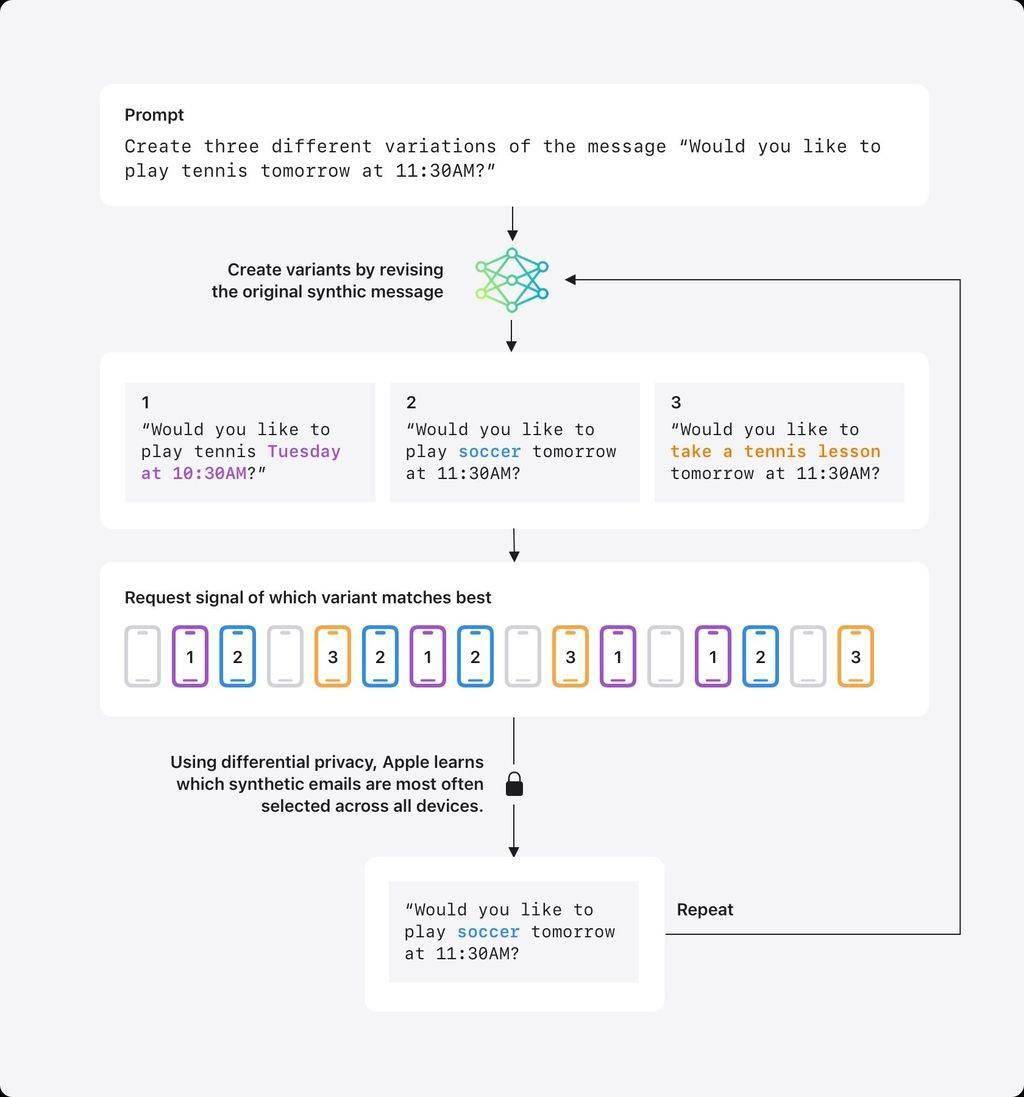
面對長文本處理的挑戰,如郵件摘要功能,蘋果開發了一套獨特的合成數據解決方案。他們首先利用大型語言模型生成大量虛擬郵件,并將其轉換為包含主題和語言特征的數字向量。隨后,參與計劃的設備會在本地計算真實郵件的向量,并通過差分隱私技術匿名反饋與合成向量最為接近的類型。經過多次迭代,系統能夠構建出一個反映真實郵件分布規律的合成數據集,而無需接觸任何原始郵件內容。這一技術已在郵件摘要功能的測試版中得到了驗證,并計劃未來應用于寫作助手等其他場景。
蘋果在博文中明確指出,Apple Intelligence服務的所有模型訓練均使用去標識化數據,并在訓練前嚴格過濾掉如社交安全號等敏感信息。這體現了蘋果在技術發展過程中,始終將用戶隱私放在首位的原則。
蘋果還透露,即將發布的iOS 18.5等系統中,差分隱私和合成數據技術將進一步擴展到Image Wand圖像處理、記憶相冊生成等十余項功能中。蘋果強調,即使用戶參與設備分析計劃,其個人數據也始終在本地以加密形式存儲,公司僅能獲取經過數學驗證的群體趨勢報告,從而確保用戶隱私的絕對安全。