在靜謐的夜晚,全球AI開發者們迎來了一場意想不到的驚喜。沒有盛大的發布會,沒有鋪天蓋地的新聞稿,甚至連基本的更新說明都付諸闕如,但中國開源大模型DeepSeek的又一次飛躍,卻在凌晨兩點的默默更新中,被全球的技術愛好者共同見證。
與OpenAI、Anthropic等巨頭的高調發布模式截然不同,DeepSeek此次更新采取了近乎隱秘的方式。僅在微信群內簡短通知后,工程師團隊便于29日凌晨將最新版本悄然上傳至HuggingFace平臺,連模型卡片都未及更新,便匆匆離去,留下滿世界的開發者們自行探索。
這種低調行事,幾乎成為了DeepSeek的獨特標識。今年3月,當V3模型悄然問世時,同樣未引起廣泛關注,直到開發者們自行測試,才發現其性能已悄然超越了Claude 3.7 Sonnet。業內有人猜測,DeepSeek團隊或許認為,只要模型架構未發生根本性變化,便不足以構成大版本升級,這種務實態度,彰顯了中國團隊對技術本質的深刻洞察。
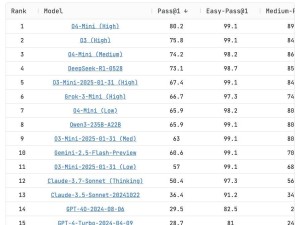
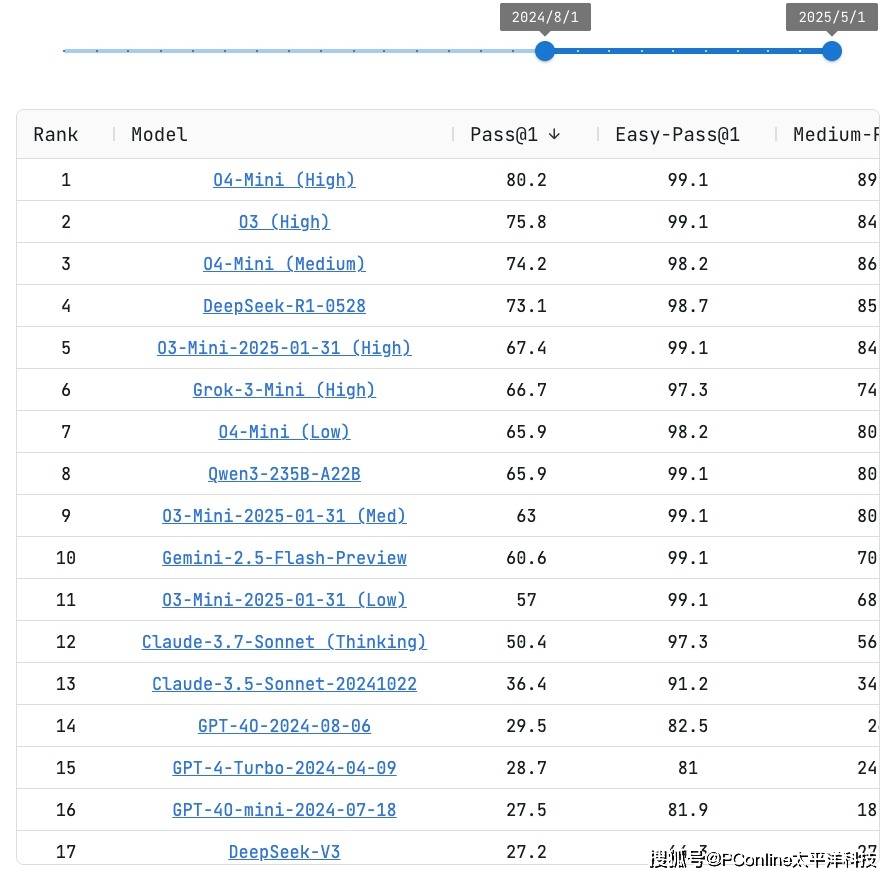
盡管官方未對新版本性能做出任何說明,但全球開發者社區卻迅速自發組織起對新模型的全面測試。測試結果令人驚嘆不已:在權威編程評測平臺Live CodeBench上,DeepSeek-R1-0528的得分緊隨OpenAI o4-Mini(Medium)之后,位列第四。要知道,這些都是OpenAI旗下的高性能商業模型,而DeepSeek-R1-0528不僅性能接近,更重要的是它開源且免費。
一位開發者嘗試讓DeepSeek-R1-0528編寫一個俄羅斯方塊網頁游戲,僅思考9秒后,它便一次性完成了所有代碼,并且可以直接在網頁上運行。經過仔細測試,游戲運行流暢,界面設計也頗為出色,讓人不禁感嘆其強大的代碼生成能力。
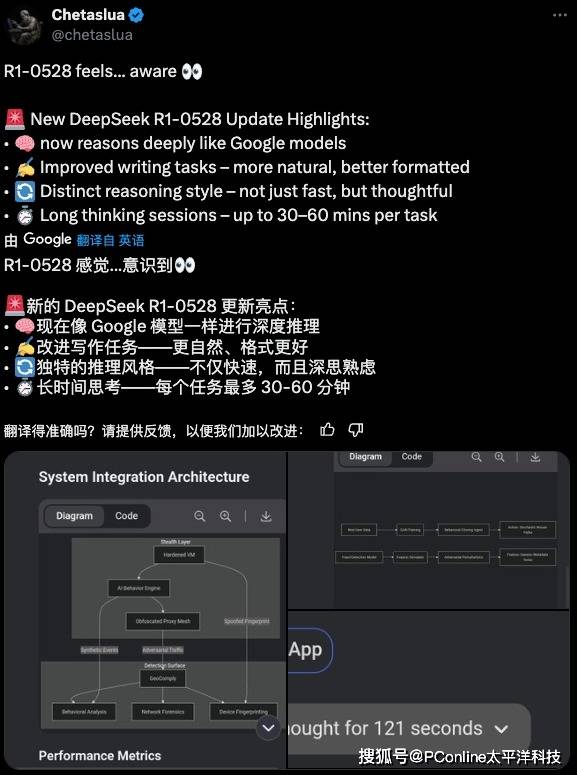
除了代碼能力之外,新模型在其他方面也取得了顯著進步。其寫作風格更加正常化,早期版本中用戶詬病的“量子力學式表達”問題得到了明顯改善,輸出更加自然流暢;結構化思維顯著增強,在解決復雜問題時展現出清晰的思維鏈條和嚴密的邏輯推進;長文本處理能力也有所優化,在32K上下文長度內,文本召回準確率明顯提升。
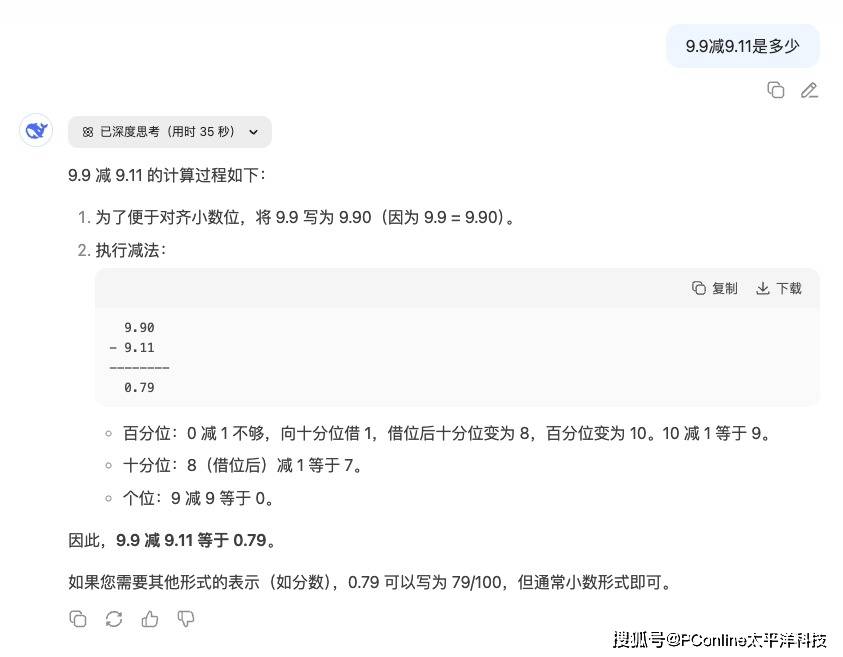
最引人注目的,莫過于新模型新增的長時思考能力。新R1單任務處理時間可達30-60分鐘,有用戶實測遇到模型“長考”212秒才給出答案,遠超之前版本。這種深度思考機制,使其成為目前唯一能持續正確回答“9.9減9.11是多少”的模型。
R1的驚艷表現,引發了全球AI社區對R2的無限遐想。在社交媒體上,關于R1升級的討論下,充斥著對R2的詢問和期待。據傳,R2將采用混合專家模型(MoE)架構,參數量高達1.2萬億,較R1提升80%,推理成本大幅降低,性價比突破想象,芯片利用率高達82%。

更值得注意的是,DeepSeek與清華大學聯合發布的《自我原則點評調優》(SPCT)論文,提出了元獎勵模型(meta RM)新方法,被視為R2的技術前兆。這一系列舉措,不僅展示了DeepSeek團隊在技術研發上的深厚底蘊,也揭示了中國AI團隊獨特的發展哲學:不重版本號,只重實際能力提升。
當商業公司熱衷于通過版本迭代制造營銷熱點時,DeepSeek卻將資源投入到實質性能突破上。這種務實精神,帶來了驚人的性價比。DeepSeek-V3-0324的輸入成本僅為Claude Sonnet 3.7的1/11,GPT-4.5的1/277。而新R1作為開源模型,其性能卻直逼天價商業產品。這不僅是對開源精神的勝利,更是對整個AI行業創新速度的極大推動。