近期,科技領域迎來了一波新的模型發布高潮,其中OpenAI推出的GPT-4.1系列模型尤為引人注目。據bleepingcomputer報道,這一最新版本相較于其前身GPT-4o,在性能上實現了顯著飛躍。
OpenAI于4月15日正式揭曉了GPT-4.1、GPT-4.1 mini及GPT-4.1 nano三款新模型。從官方公布的跑分數據來看,這些新模型在編程能力上有了質的飛躍,遠遠超越了GPT-4o及其小型版本GPT-4o mini。以SWE-bench Verified跑分為例,GPT-4o僅獲得了21.4%的分數,而GPT-4.1則一舉躍升至54.6%,展現出了強大的編程實力。
然而,盡管GPT-4.1系列模型在性能上取得了顯著提升,但在與谷歌Gemini系列的對比中,卻并未能占據上風。根據Stagehand發布的基準數據,Gemini 2.0 Flash在錯誤率和精確匹配率上均表現優異,錯誤率僅為6.67%,精確匹配率高達90%,且價格更為親民,速度更快。相比之下,GPT-4.1的錯誤率則高達16.67%,成本更是Gemini 2.0 Flash的十倍以上。
來自哈佛大學的RNA科學家Pierre Bongrand也提供了相關數據,進一步印證了GPT-4.1在性價比方面的不足。他指出,相較于Gemini 2.0 Flash、Gemini 2.5 Pro及DeepSeek等競品,GPT-4.1的性價比并不具備優勢。

在編碼專項測試中,GPT-4.1的表現同樣未能讓人眼前一亮。Aider Polyglot的測試結果顯示,GPT-4.1的編碼得分僅為52%,而谷歌的Gemini 2.5則以73%的得分遙遙領先,進一步凸顯了GPT-4.1在編碼能力上的不足。
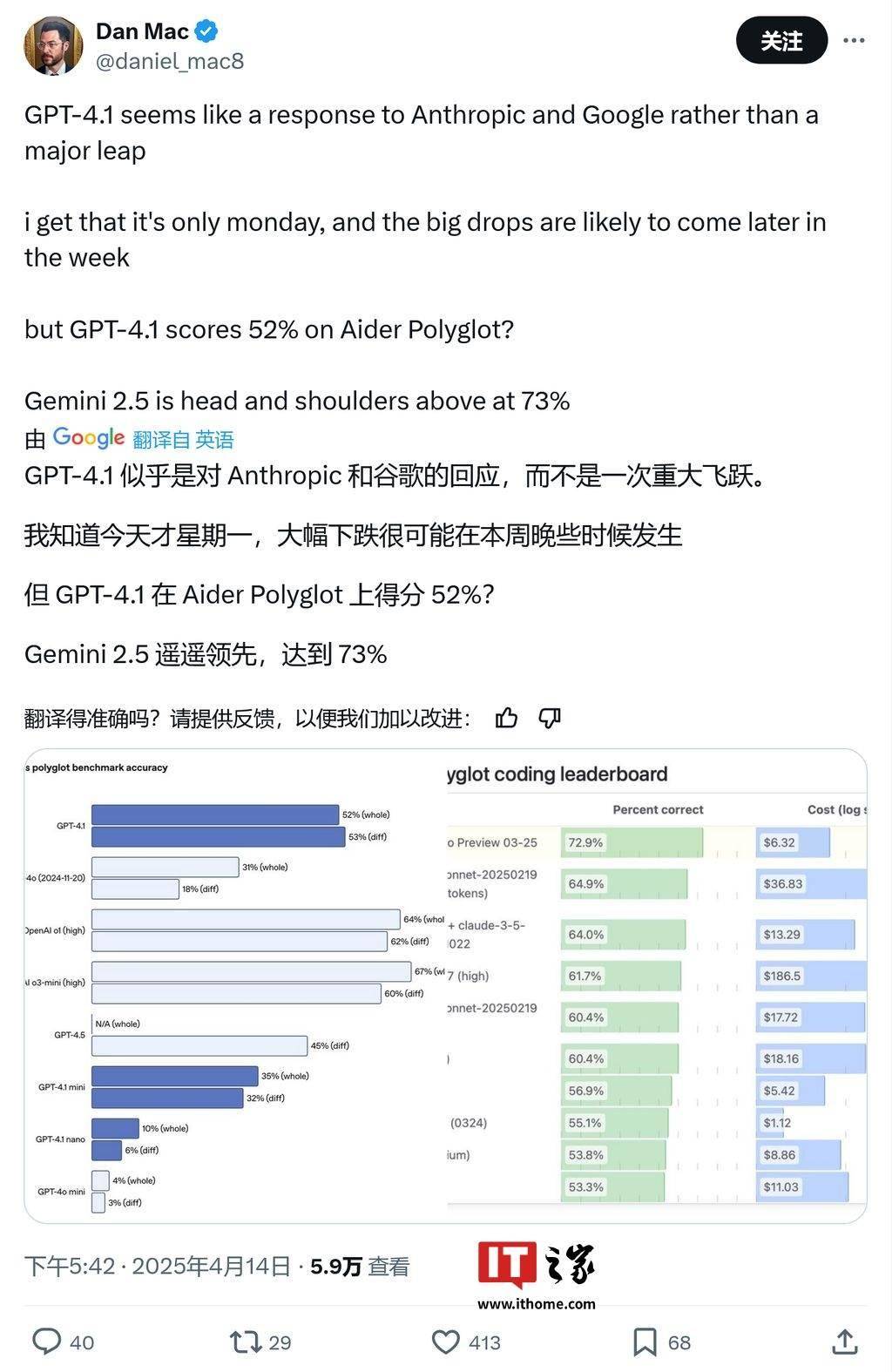
值得注意的是,盡管GPT-4.1被歸類為非推理模型,但其在編碼能力方面依然處于行業領先地位。這一成績無疑為OpenAI的AI研發實力提供了有力證明,同時也為未來的AI模型發展提供了更多可能性。
然而,在與谷歌Gemini系列的對比中,GPT-4.1也暴露出了自身在性價比和錯誤率方面的不足。這提醒我們,在AI技術的快速發展中,仍需不斷追求性能與成本的平衡,以更好地滿足實際應用需求。