OpenAI近日在人工智能技術領域邁出了重要一步,于3月20日正式宣布推出全新的語音轉文本(speech-to-text)及文本轉語音(text-to-speech)模型,旨在顯著提升語音處理能力,并為開發者提供更加精確、高度可定制的語音交互系統解決方案。這一舉措預示著人工智能語音技術商業化應用的進一步加速。
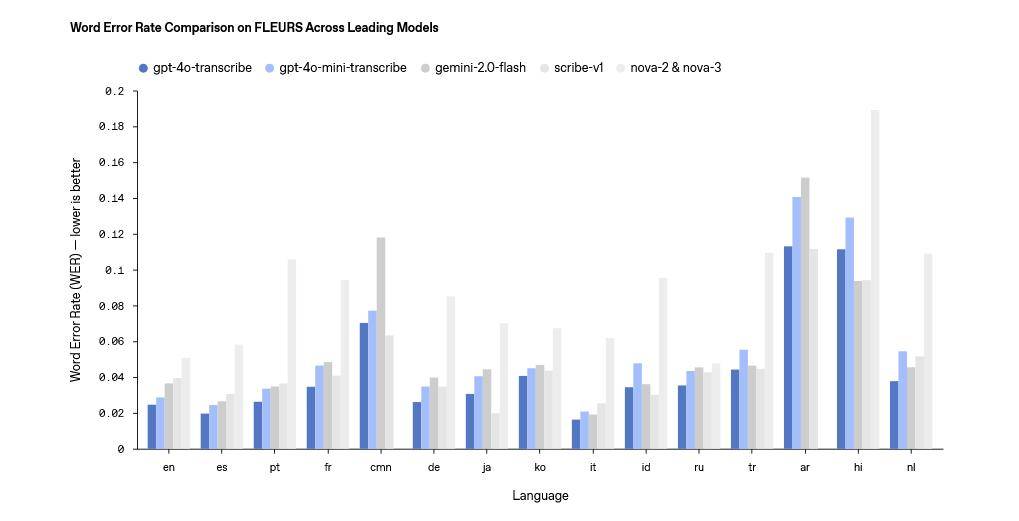
在語音轉文本領域,OpenAI推出了gpt-4o-transcribe和gpt-4o-mini-transcribe兩款模型,據官方宣稱,這兩款模型在單詞錯誤率(WER)、語言識別精度以及整體準確性方面,均超越了其現有的Whisper系列模型。它們能夠支持超過100種語言,通過強化學習和多樣化高質量音頻數據集的深入訓練,成功捕捉語音中的細微特征,有效減少誤識別情況,特別是在嘈雜環境、不同口音及語速變化下,展現出更加穩定的性能。
這兩款新模型的問世,無疑為開發者提供了更為強大的工具,使他們能夠構建出更加精準、適應性更強的語音交互系統,滿足不同場景下的需求。無論是智能客服、智能家居,還是自動駕駛等領域,都將因此受益。
在文本轉語音方面,OpenAI同樣推出了創新的gpt-4o-mini-tts模型。這款模型允許開發者通過簡單的指令,如“模擬耐心客服”或“生動故事敘述”,來控制語音的風格和語調。這一特性使得gpt-4o-mini-tts在客服領域具有巨大潛力,能夠合成更具同理心的語音,從而顯著提升用戶體驗。同時,它也為創意內容制作帶來了無限可能,如有聲書錄制、游戲角色配音等。

為了幫助開發者更好地了解和使用這些新模型,OpenAI還公布了詳細的費用說明。gpt-4o-transcribe模型在處理音頻輸入時,每100萬tokens的費用為6美元,文本輸入和輸出的費用分別為2.5美元和10美元,每分鐘的成本為0.6美分。相比之下,gpt-4o-mini-transcribe模型的費用更加親民,音頻輸入、文本輸入和輸出的費用分別為3美元、1.25美元和5美元,每分鐘的成本僅為0.3美分。而gpt-4o-mini-tts模型則按輸入和輸出分別計費,每100萬tokens的輸入費用為0.6美元,輸出費用為12美元,每分鐘的成本為1.5美分。
OpenAI此次推出的新模型,不僅展示了其在人工智能技術領域的深厚積累和創新實力,也為整個行業樹立了新的標桿。隨著這些模型的不斷優化和推廣,人工智能語音技術將在更多領域發揮重要作用,推動社會進步和產業發展。